Source: Table Loading Strategies in Data warehousing
In Data Warehouses variety of tables are needed to create and maintain as per their different consumption patterns. There are certain strategies to load these tables considering their usage, data size, refresh frequencies, etc. This blog tries to explain some of these strategies which are mostly used in data warehousing.
- Unpartitioned tables with simple insert: These tables are not partitioned and we simply insert data into them.
Pros:
- Fact tables(transactional data), bridge tables(mappings) can be created using this strategy.
- This strategy can be preferred, if the source keeps generating a large amount of new data on a regular basis.
Cons:
- As the “insert” clause is used, we need to be cautious while inserting data to avoid data duplication. Table level constraints can be added here if target storage is RDBMS but it becomes complex in the case of Big Data. Usually, such constraints are handled in the ‘insert’ logic itself in these scenarios.
- As tables are not partitioned, it became tricky to separate out correct and incorrect data or fix duplication issues, etc if no unique key constraints exist on the table.
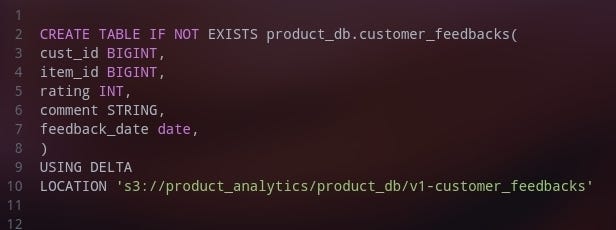
For Example, let’s create a table for customer feedback as below without any partitioning.
Please note that SQL queries/statements given here, are just skeletons and not the actual executable queries.
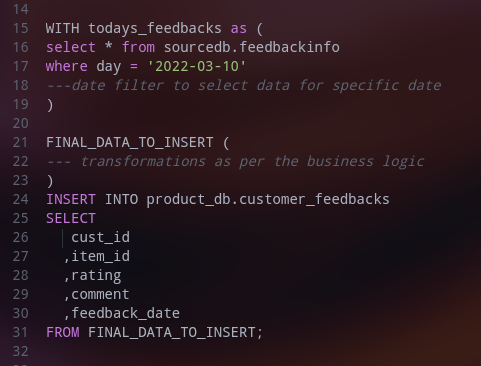
Insert Strategy: We use an insert statement if only new data is supposed to come from the source for a given date. Further to check if data already exists or not, we can use left outer join as well using row key hash. Below is the sample SQL statement for the same.
2. Insert Overwrite or Truncate-load Tables: These are small tables in terms of the number of rows and size in bytes. Usually, datasets like summary, overview, aggregated data over a complete period of time, or specific period like a current day, current week, current month can be stored as “Insert Overwrite” tables.
Pros:
- Good for a small amount of data.
- Being smaller in size, truncating and loading such a tables on regular basis is not an expensive operation.
- Datasets with simple logic without any complex transformations, etc can be stored in these tables.
- No Need for backfilling for these tables.
Cons:
- Not good for heavy data and complex business logic
- The history of the data can not be tracked
Considering the same table DDL as above, this time we will insert with OVERWRITE strategy as below.
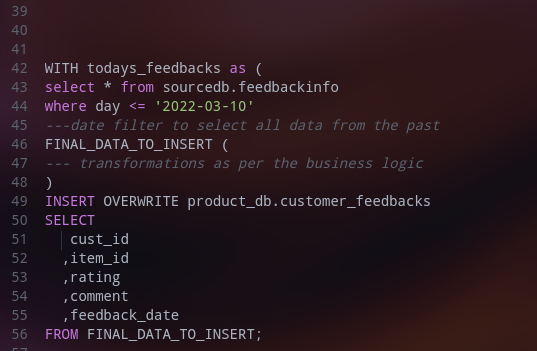
3. Snapshot Table: These tables are partitioned tables and usually partitioning column belongs to the time dimension like, day/date or hour, Month, year, etc. New data is added as a new partition.No change is made in existing/older partition or data(No Updates).
Pros:
- Enables a complete view (Snapshot) of the data at a given point in time.
- No complex logic for inserting data, simple INSERT OVERWRITE PARTITION strategy is used.
- No need to check SCD columns like version, scd_date_from, scd_date_to, version,current_record_flag, etc to check the state of the data in a particular time frame. We just need to filter data with a partitioning column.
- Fact tables can be created as Snapshot tables to load daily/hourly transactional data.
- Being INSERT OVERWRITE strategy, no need to worry about data duplication issues as partitions are being overwritten by erasing existing data in it.
Cons:
- Rather than capturing changed data, complete data is copied regularly, which leads to large consumption of space over time.
- Data loading on a regular basis is a heavy operation in terms of time and computing cost as every time you need to load all rows from the source.
- Backfilling these tables become a heavy expensive operation over time as we need to reload every partition again.
- Not recommended if large data in the source and daily addition to it is too large in terms of the number of rows and size in bytes.
For example, create table customer feedbacks with feedback date as a column for the partitioning as below:
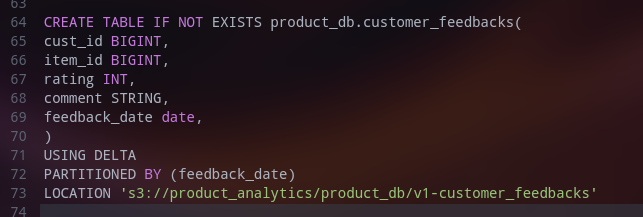
Now, we will use the Insert Overwrite Partition clause as below:

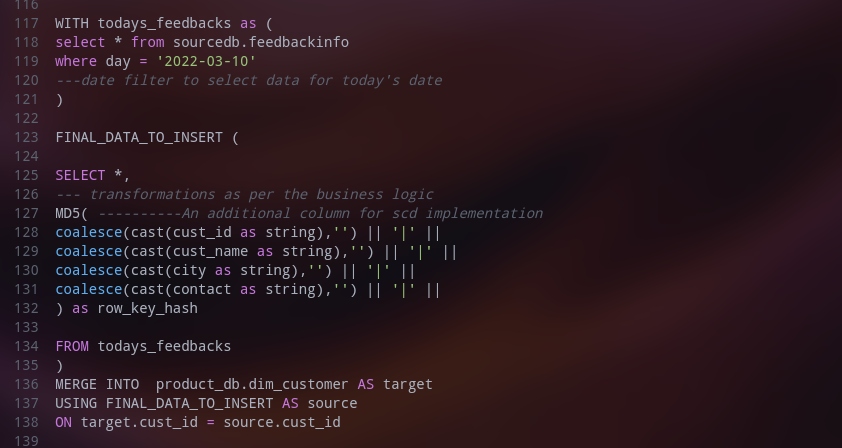
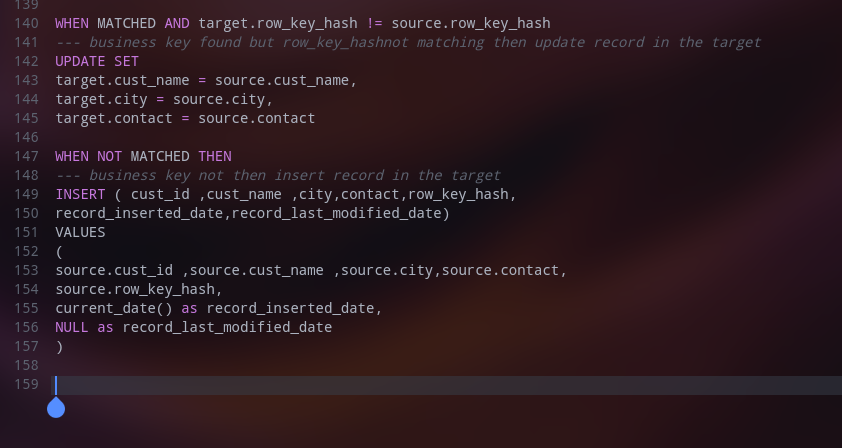
4. Merging Data with SCD type 1 Strategy: It’s based on the concept of a slowly changing dimension (Type I). This Strategy is mainly used for dimension tables. It has two rules as below:
a. If a business key is new in the source and absents in the target, insert it as it is into the target.
b. If a business key exists in the target but a few columns/attributes are changed, then update them in the target.
While doing the above operation, no version history of the data is maintained.
For example below is the customer dimension table with SCD Type 1 strategy.

5. Merging Data with SCD type 2 Strategy:
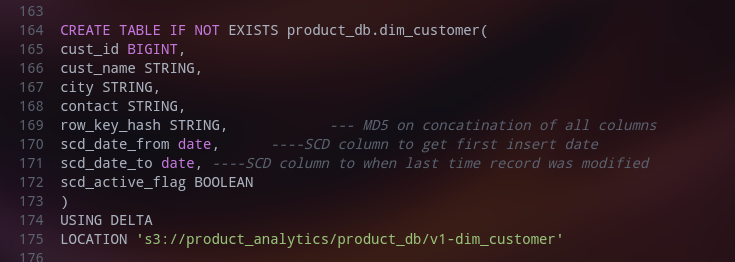
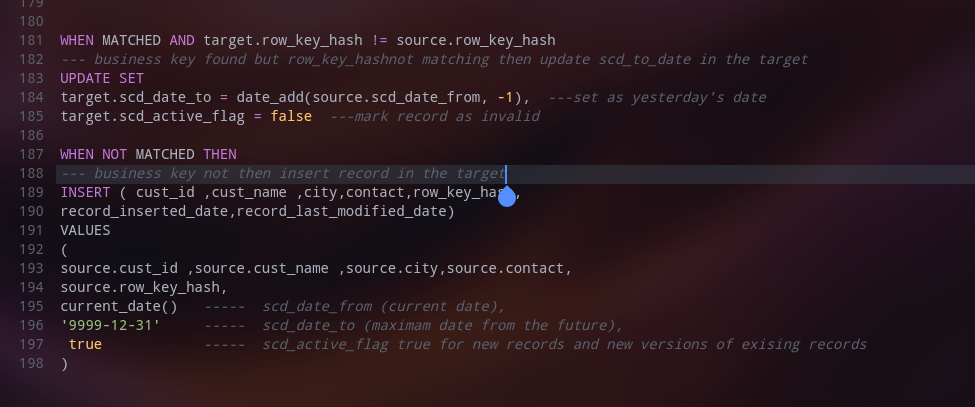
Similar to SCD I, this too is based on the concept of the slowly changing dimension (Type II) and is mainly used for dimension tables. It has two rules as below:
a. If a business key is new in the source and absents in the target, insert it as it is into the target.
b. If a business key exists in the target but a few columns/attributes are not matching then mark that record as inactive and insert a changed new record from the source as an active record.
While performing this, the version history of the data is maintained as well.A various approaches like date range (scd_date_from,scd_date_to) , version, current_record_flag etc can be used to implement this.
Here, we use the MERGE clause from SQL to perform this operation as below:
These approaches are based on what we implemented in the past, but yes there are certain areas to improve them further. Happy to hear suggestions, recommendations and corrections to them.